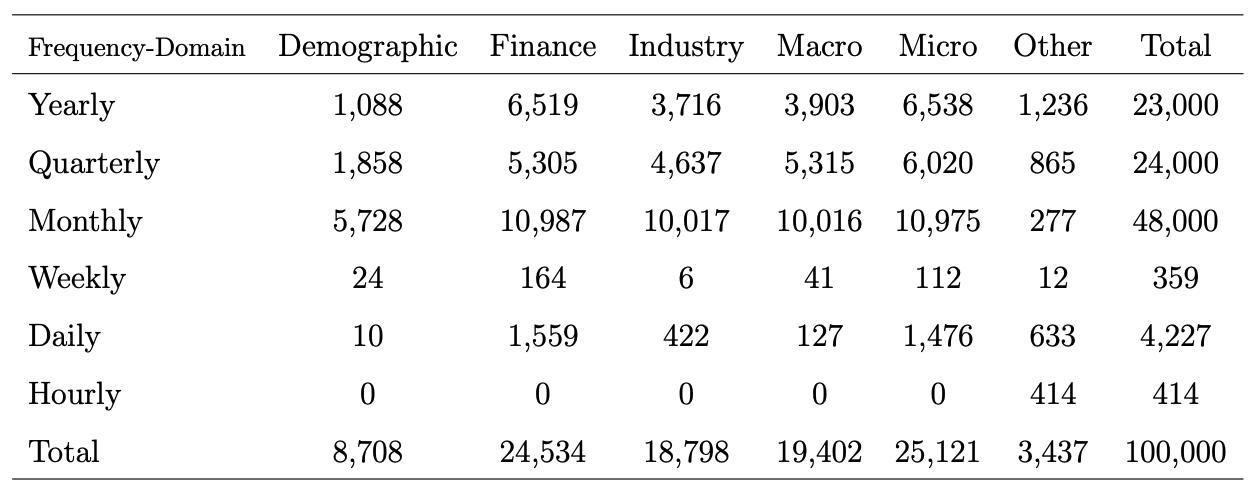
The M4 dataset is a collection of 100,000 time series used for the fourth edition of the Makridakis forecasting Competition. The M4 dataset consists of time series of yearly, quarterly, monthly and other (weekly, daily and hourly) data, which are divided into training and test sets. The minimum numbers of observations in the training test are 13 for yearly, 16 for quarterly, 42 for monthly, 80 for weekly, 93 for daily and 700 for hourly series. The participants were asked to produce the following numbers of forecasts beyond the available data that they had been given: six for yearly, eight for quarterly, 18 for monthly series, 13 for weekly series and 14 and 48 forecasts respectively for the daily and hourly ones.
The M4 dataset was created by selecting a random sample of 100,000 time series from the ForeDeCk database. The selected series were then scaled to prevent negative observations and values lower than 10, thus avoiding possible problems when calculating various error measures. The scaling was performed by simply adding a constant to the series so that their minimum value was equal to 10 (29 occurrences across the whole dataset). In addition, any information that could possibly lead to the identification of the original series was removed so as to ensure the objectivity of the results. This included the starting dates of the series, which did not become available to the participants until the M4 had ended.
Source: The M4 competition: Results, findings, conclusion and way forwardPapers
| Paper | Code | Results | Date | Stars |
|---|


