InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding
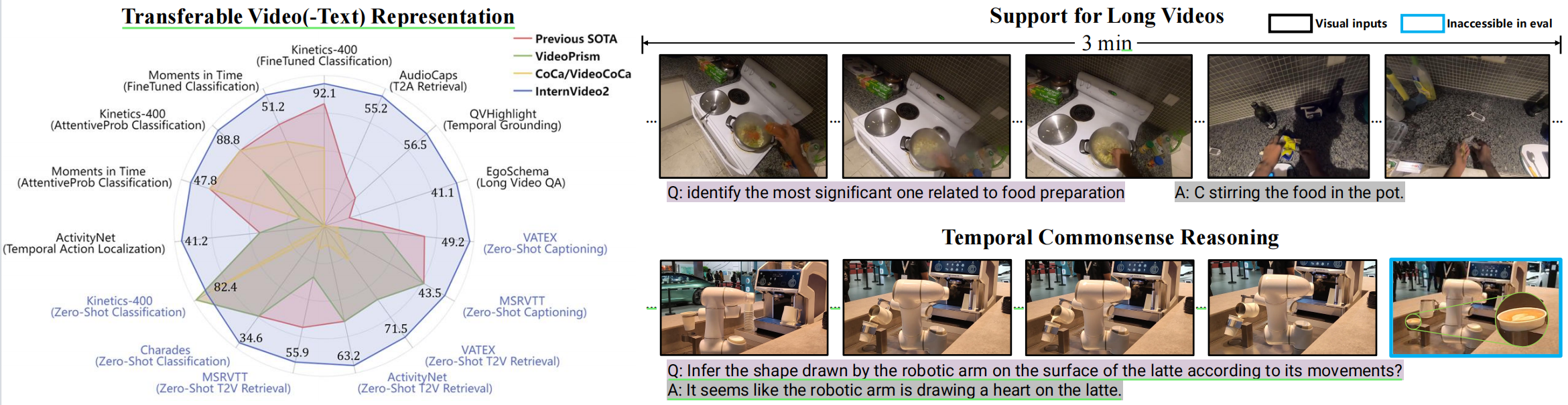
We introduce InternVideo2, a new video foundation model (ViFM) that achieves the state-of-the-art performance in action recognition, video-text tasks, and video-centric dialogue. Our approach employs a progressive training paradigm that unifies the different self- or weakly-supervised learning frameworks of masked video token reconstruction, cross-modal contrastive learning, and next token prediction. Different training stages would guide our model to capture different levels of structure and semantic information through different pretext tasks. At the data level, we prioritize the spatiotemporal consistency by semantically segmenting videos and generating video-audio-speech captions. This improves the alignment between video and text. We scale both data and model size for our InternVideo2. Through extensive experiments, we validate our designs and demonstrate the state-of-the-art performance on over 60 video and audio tasks. Notably, our model outperforms others on various video-related captioning, dialogue, and long video understanding benchmarks, highlighting its ability to reason and comprehend long temporal contexts. Code and models are available at https://github.com/OpenGVLab/InternVideo2/.
PDF AbstractCode

Tasks
 Action Classification
Action Classification
 Action Recognition
Action Recognition
 Audio Classification
Audio Classification
 Contrastive Learning
Contrastive Learning
 Moment Retrieval
Moment Retrieval
 Temporal Action Localization
Text to Audio Retrieval
Video Grounding
Temporal Action Localization
Text to Audio Retrieval
Video Grounding
 Video Instance Segmentation
Video Retrieval
Video Understanding
Weakly-supervised Learning
Zero-shot Text to Audio Retrieval
Zero-Shot Video Question Answer
Zero-Shot Video Retrieval
Video Instance Segmentation
Video Retrieval
Video Understanding
Weakly-supervised Learning
Zero-shot Text to Audio Retrieval
Zero-Shot Video Question Answer
Zero-Shot Video Retrieval
 UCF101
UCF101
 Kinetics
Kinetics
 HMDB51
HMDB51
 ActivityNet
ActivityNet
 Kinetics 400
Kinetics 400
 MSR-VTT
MSR-VTT
 ESC-50
ESC-50
 THUMOS14
THUMOS14
 MSVD
MSVD
 Something-Something V2
Something-Something V2
 Charades-STA
Charades-STA
 DiDeMo
DiDeMo
 AudioCaps
AudioCaps
 YouTube-VIS 2019
YouTube-VIS 2019
 Clotho
Clotho
 Kinetics-600
Kinetics-600
 LSMDC
LSMDC
 VATEX
VATEX
 MiT
MiT
 Kinetics-700
Kinetics-700
 HACS
HACS
 QVHighlights
QVHighlights
 FineAction
FineAction
| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Video Retrieval | ActivityNet | InternVideo2-6B | text-to-video R@1 | 74.1 | # 1 | ||
| video-to-text R@1 | 69.7 | # 1 | |||||
| Zero-Shot Video Retrieval | ActivityNet | InternVideo2-6B | text-to-video R@1 | 63.2 | # 1 | ||
| video-to-text R@1 | 56.5 | # 1 | |||||
| text-to-video R@10 | 92.5 | # 1 | |||||
| text-to-video R@5 | 85.6 | # 1 | |||||
| video-to-text R@5 | 82.8 | # 1 | |||||
| video-to-text R@10 | 90.3 | # 1 | |||||
| Zero-Shot Video Retrieval | ActivityNet | InternVideo2-1B | text-to-video R@1 | 60.4 | # 2 | ||
| video-to-text R@1 | 54.8 | # 2 | |||||
| text-to-video R@10 | 90.8 | # 2 | |||||
| text-to-video R@5 | 83.9 | # 2 | |||||
| video-to-text R@5 | 81.5 | # 2 | |||||
| video-to-text R@10 | 89.5 | # 2 | |||||
| Action Recognition | ActivityNet | InternVideo2-6B | mAP | 95.9 | # 3 | ||
| Temporal Action Localization | ActivityNet-1.3 | InternVideo2-6B | mAP | 41.2 | # 4 | ||
| Temporal Action Localization | ActivityNet-1.3 | InternVideo2-1B | mAP | 40.4 | # 5 | ||
| Text to Audio Retrieval | AudioCaps | InternVideo2-6B | R@1 | 55.2 | # 1 | ||
| Zero-shot Text to Audio Retrieval | AudioCaps | InternVideo2-6B | Audio-to-text R@1 | 37.1 | # 1 | ||
| Moment Retrieval | Charades-STA | InternVideo2-1B | R@1 IoU=0.5 | 68.36 | # 2 | ||
| R@1 IoU=0.7 | 45.03 | # 2 | |||||
| Moment Retrieval | Charades-STA | InternVideo2-6B | R@1 IoU=0.5 | 70.03 | # 1 | ||
| R@1 IoU=0.7 | 48.95 | # 1 | |||||
| Zero-shot Text to Audio Retrieval | Clotho | InternVideo2-6B | text-to-audio R@1 | 17.4 | # 1 | ||
| Text to Audio Retrieval | Clotho | InternVideo2-6B | R@1 | 27.2 | # 1 | ||
| Zero-Shot Video Retrieval | DiDeMo | InternVideo2-6B | text-to-video R@1 | 57.9 | # 1 | ||
| text-to-video R@5 | 80.0 | # 1 | |||||
| text-to-video R@10 | 84.6 | # 2 | |||||
| video-to-text R@1 | 57.1 | # 1 | |||||
| video-to-text R@5 | 79.9 | # 1 | |||||
| video-to-text R@10 | 85.0 | # 1 | |||||
| Video Retrieval | DiDeMo | InternVideo2-6B | text-to-video R@1 | 74.2 | # 1 | ||
| video-to-text R@1 | 71.9 | # 1 | |||||
| Zero-Shot Video Retrieval | DiDeMo | InternVideo2-1B | text-to-video R@1 | 57.0 | # 2 | ||
| text-to-video R@5 | 80.0 | # 1 | |||||
| text-to-video R@10 | 85.1 | # 1 | |||||
| video-to-text R@1 | 54.3 | # 2 | |||||
| video-to-text R@5 | 77.2 | # 2 | |||||
| video-to-text R@10 | 83.5 | # 3 | |||||
| Zero-Shot Video Question Answer | EgoSchema (fullset) | InternVideo2-6B | Accuracy | 41.1 | # 4 | ||
| Audio Classification | ESC-50 | InternVideo2 | Top-1 Accuracy | 98.6 | # 1 | ||
| PRE-TRAINING DATASET | Multiple | # 1 | |||||
| Accuracy (5-fold) | 98.6 | # 1 | |||||
| Temporal Action Localization | FineAction | InternVideo2-6B | mAP | 27.7 | # 2 | ||
| Temporal Action Localization | HACS | InternVideo2-1B | Average-mAP | 42.4 | # 4 | ||
| Action Recognition | HACS | InternVideo2-6B | Top 1 Accuracy | 97.0 | # 1 | ||
| Temporal Action Localization | HACS | InternVideo2-6B | Average-mAP | 43.3 | # 2 | ||
| Action Classification | Kinetics-400 | InternVideo2-6B | Acc@1 | 92.1 | # 1 | ||
| Action Classification | Kinetics-400 | InternVideo2-1B | Acc@1 | 91.6 | # 2 | ||
| Action Classification | Kinetics-600 | InternVideo2-6B | Top-1 Accuracy | 91.9 | # 1 | ||
| Action Classification | Kinetics-600 | InternVideo2-1B | Top-1 Accuracy | 91.6 | # 3 | ||
| Action Classification | Kinetics-700 | InternVideo2-1B | Top-1 Accuracy | 85.4 | # 2 | ||
| Action Classification | Kinetics-700 | InternVideo2-6B | Top-1 Accuracy | 85.9 | # 1 | ||
| Zero-Shot Video Retrieval | LSMDC | InternVideo2-6B | text-to-video R@1 | 33.8 | # 1 | ||
| video-to-text R@1 | 30.1 | # 1 | |||||
| text-to-video R@5 | 55.9 | # 1 | |||||
| text-to-video R@10 | 62.2 | # 1 | |||||
| video-to-text R@5 | 47.7 | # 1 | |||||
| video-to-text R@10 | 54.8 | # 1 | |||||
| Video Retrieval | LSMDC | InternVideo2-6B | text-to-video R@1 | 46.4 | # 1 | ||
| video-to-text R@1 | 46.7 | # 1 | |||||
| Zero-Shot Video Retrieval | LSMDC | InternVideo2-1B | text-to-video R@1 | 32.0 | # 2 | ||
| video-to-text R@1 | 27.3 | # 2 | |||||
| text-to-video R@5 | 52.4 | # 2 | |||||
| text-to-video R@10 | 59.4 | # 2 | |||||
| video-to-text R@5 | 44.2 | # 2 | |||||
| video-to-text R@10 | 51.6 | # 2 | |||||
| Action Classification | MiT | InternVideo2-6B | Top 1 Accuracy | 51.2 | # 1 | ||
| Action Classification | MiT | InternVideo2-1B | Top 1 Accuracy | 50.9 | # 2 | ||
| Video Retrieval | MSR-VTT | InternVideo2-6B | text-to-video R@1 | 62.8 | # 2 | ||
| video-to-text R@1 | 60.2 | # 2 | |||||
| Zero-Shot Video Retrieval | MSR-VTT | InternVideo2-1B | text-to-video R@1 | 51.9 | # 2 | ||
| text-to-video R@5 | 75.3 | # 2 | |||||
| text-to-video R@10 | 82.5 | # 2 | |||||
| video-to-text R@1 | 50.9 | # 2 | |||||
| video-to-text R@5 | 73.4 | # 2 | |||||
| video-to-text R@10 | 81.8 | # 2 | |||||
| Zero-Shot Video Retrieval | MSR-VTT | InternVideo2-6B | text-to-video R@1 | 55.9 | # 1 | ||
| text-to-video R@5 | 78.3 | # 1 | |||||
| text-to-video R@10 | 85.1 | # 1 | |||||
| video-to-text R@1 | 53.7 | # 1 | |||||
| video-to-text R@5 | 77.5 | # 1 | |||||
| video-to-text R@10 | 84.1 | # 1 | |||||
| Zero-Shot Video Retrieval | MSVD | InternVideo2-6B | text-to-video R@1 | 59.3 | # 1 | ||
| video-to-text R@1 | 83.1 | # 2 | |||||
| text-to-video R@5 | 84.4 | # 1 | |||||
| text-to-video R@10 | 89.6 | # 1 | |||||
| video-to-text R@5 | 94.2 | # 2 | |||||
| video-to-text R@10 | 97.0 | # 2 | |||||
| Video Retrieval | MSVD | InternVideo2-6B | text-to-video R@1 | 61.4 | # 1 | ||
| video-to-text R@1 | 85.2 | # 1 | |||||
| Zero-Shot Video Retrieval | MSVD | InternVideo2-1B | text-to-video R@1 | 58.1 | # 2 | ||
| video-to-text R@1 | 83.3 | # 1 | |||||
| text-to-video R@5 | 83.0 | # 2 | |||||
| text-to-video R@10 | 88.4 | # 2 | |||||
| video-to-text R@5 | 94.3 | # 1 | |||||
| video-to-text R@10 | 96.9 | # 3 | |||||
| Zero-Shot Video Question Answer | MVBench | InternVideo2-1B | Accuracy | 60.9 | # 1 | ||
| Video Grounding | QVHighlights | InternVideo2-1B | R@1,IoU=0.5 | 70.00 | # 2 | ||
| R@1,IoU=0.7 | 54.45 | # 2 | |||||
| Video Grounding | QVHighlights | InternVideo2-6B | R@1,IoU=0.5 | 71.42 | # 1 | ||
| R@1,IoU=0.7 | 56.45 | # 1 | |||||
| Action Recognition | Something-Something V2 | InternVideo2-6B | Top-1 Accuracy | 77.5 | # 1 | ||
| Action Recognition | Something-Something V2 | InternVideo2-1B | Top-1 Accuracy | 77.1 | # 4 | ||
| Temporal Action Localization | THUMOS’14 | InternVideo2-6B | Avg mAP (0.3:0.7) | 72.0 | # 3 | ||
| Temporal Action Localization | THUMOS’14 | InternVideo2-1B | Avg mAP (0.3:0.7) | 69.8 | # 6 | ||
| Zero-Shot Video Retrieval | VATEX | InternVideo2-1B | text-to-video R@1 | 70.4 | # 2 | ||
| video-to-text R@1 | 85.4 | # 1 | |||||
| text-to-video R@5 | 93.4 | # 2 | |||||
| text-to-video R@10 | 96.9 | # 2 | |||||
| video-to-text R@5 | 97.6 | # 2 | |||||
| video-to-text R@10 | 99.1 | # 2 | |||||
| Video Retrieval | VATEX | InternVideo2-6B | text-to-video R@1 | 75.5 | # 3 | ||
| video-to-text R@1 | 89.3 | # 1 | |||||
| Zero-Shot Video Retrieval | VATEX | InternVideo2-6B | text-to-video R@1 | 71.5 | # 1 | ||
| video-to-text R@1 | 85.3 | # 2 | |||||
| text-to-video R@5 | 94.0 | # 1 | |||||
| text-to-video R@10 | 97.1 | # 1 | |||||
| video-to-text R@5 | 97.9 | # 1 | |||||
| video-to-text R@10 | 99.3 | # 1 | |||||
| Video Instance Segmentation | YouTube-VIS validation | Mask2Former(InternVideo2-6B) | mask AP | 64.2 | # 10 |
