$R^*$: A robust MCMC convergence diagnostic with uncertainty using gradient-boosted machines
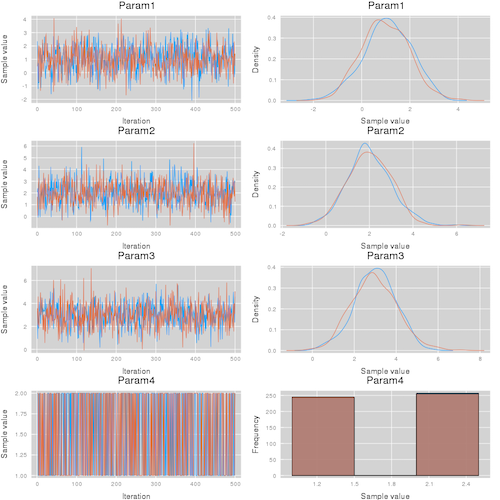
Markov chain Monte Carlo (MCMC) has transformed Bayesian model inference over the past three decades and is now a workhorse of applied scientists. Despite its importance, MCMC is a subtle beast which should be used with care. Central to these concerns is the difficulty in determining whether Markov chains have converged to the posterior distribution. The predominant method for monitoring convergence is to run multiple chains and monitor individual chains' characteristics and compare these to the population as a whole: if within-chain and between-chain summaries are comparable, then this may indicate the chains have converged to a stationary distribution. Qualitatively, these summary statistics aim to determine whether it is possible to predict the chain that generated a particular sample: if these predictions are accurate, then the chains have not mixed and convergence has not occurred. Here, we introduce a new method for probing convergence based on training machine learning algorithms to classify samples according to the chain that generated them: we call this convergence measure $R^*$. In contrast to the predominant $\hat{R}$, $R^*$ is a single statistic across all parameters that captures whether convergence has occurred, although individual variables' importance for this metric can also be determined. Additionally, $R^*$ is not based on any single characteristic of the sampling distribution; instead using all the information in the chain, including that given by the joint sampling distributions, which is currently largely overlooked by existing approaches. Since our machine learning method, gradient-boosted regression trees (GBM), provides uncertainty in predictions, as a byproduct, we obtain uncertainty in $R^*$. The method is straightforward to implement, robust to GBM hyperparameter choice, and could be a complementary additional check on MCMC convergence for applied analyses.
PDF Abstract